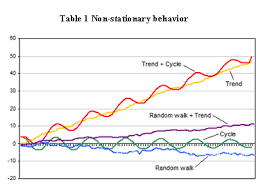
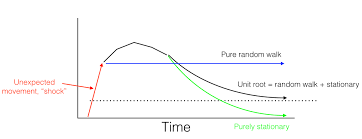
problem with unit root

John Cochrane responds to my piece on why there is no evidence that the economy is self-correcting with an excellent blog post on unit roots. John's post raises two issues. The first is descriptive statistics. What is a parsimonious way to describe the time series properties of the unemployment rate? Unemployment is the sum of a persistent component and a transitory component. The second is economics. How should we interpret the permanent component? I claim that the permanent component is caused by shifts from one equilibrium to another and that each of these equilibria is associated with a different permanent unemployment rate. I’ll call that the “demand side theory”. (More on the data here and here and my perspective on the theory here and here). Modern macroeconomics interprets the permanent component as shifts in the natural rate of unemployment. I’ll call that the “supply side theory”. That theory is widely accepted and, in my view, wrong. As I predicted in the Financial Times back in 2009, "the next [great economic idea] to fall will be the natural rate hypothesis".

My answer is that aggregate demand, driven by animal spirits, is pulling the economy from one inefficient equilibrium to another. My theoretical work explains h If permanent movements in the unemployment rate are caused by shifts in aggregate demand, as I believe, we can and should be reacting against these shifts by steering the economy back to the socially optimal unemployment rate. If instead, these movements are caused by shifts in aggregate supply, the moving target is the socially optimal unemployment rate.John has not yet staked out a position. On this point he says… Paul Krugman weighed in on this debate and he claims to agree with John about the statistics, although I’m not sure he read the comments section. Tired old 1950's theory would attribute the permanent component in unemployment to unavoidable natural rate shifts. Shiny new Neo-Paleo-Keynesian theory would attribute the permanent component to avoidable shifts in animal spirits. Which is it Paul: Demand or Supply?

< Previous Next > A Sequential Procedure for Testing Unit Roots in the Presence of Structural Break in Time Series Data Testing for unit roots has special significance in terms of both economic theory and the interpretation of estimation results.
york air conditioning parts onlineAs there are several methods available, researchers face method selection problem while conducting the unit root test on time series data in the presence of structural break.
ac motor control basicsThis paper proposes a sequential search procedure to determine the best test method for each time series.
window ac unit accessoriesDifferent test methods or models may be appropriate for different time series. Therefore, instead of sticking to one particular test method for all the time series under consideration, selection of a set of mixed methods is recommended for obtaining better results.

Sign up or log in to customize your list.BackgroundBreak VariablesThe ModelInnovational Outlier TestsAdditive Outlier TestsTest OptionsLag SelectionBreak Date SelectionComputing a Unit Root with Breakpoint TestExamplesReal GNPEmploymentGNP DeflatorThe use of unit root tests to distinguish between trend and difference stationary data has become an essential tool in applied research. Accordingly, EViews offers a variety of standard unit root tests, including augmented Dickey-Fuller (ADF), Phillips-Perron (PP), Elliot, Rothenberg, and Stock (ERS), Ng and Perron (NP), and Kwiatkowski, Phillips, Schmidt, and Shin (KPSS) tests (“Unit Root Testing”).Before proceeding, it will be useful to define a few variables which allow us to characterize the breaks. Let be an indicator function that takes the value 1 if the argument is true, and 0 otherwise. Then the following variables are defined in terms of a specified break date ,where are innovations, and is a lag polynomial representing the dynamics of the stationary and invertible ARMA error process.

Note that the break variables enter the model with the same dynamics as the innovations.and use the for comparing to 1 () to evaluate the null hypothesis. As with conventional Dickey-Fuller unit root test equations, the lagged differences of the are included in the test equations to eliminate the effect of the error correlation structure on the asymptotic distribution of the statistic.Within this general framework, we may specify different models for the null and alternative by placing zero restrictions on one or more of the trend and break parameters , , . Following Perron (1989), Perron and Vogelsang (1992a, 1992b), and Vogelsang and Perron (1998), we consider four distinct specifications for the Dickey-Fuller regression which correspond to different assumptions for the trend and break behavior:Setting the trend and trend break coefficients and to zero yields a test of a random walk against a stationary model with intercept break.Setting the trend break coefficient to zero produces a test of a random walk with drift against a trend stationary model with intercept break.

Setting the intercept break and break dummy coefficients and to zero tests a random walk with drift null against a trend stationary with trend break alternative. Note that the test equation for Model 3 follows the methodology of Zivot and Andrews (1992) and Banerjee (1992) which does not nest the null and alternatives, as is absent from the test equation; see Vogelsang and Perron (1998), p. 1077 for discussion.If the break date is estimated, the test statistics considered here do not permit a breaking trend under the null. Vogelsang and Perron (1998) offer a detailed discussion of this point, noting that this undesirable restriction is required to obtain distributional results for the resulting Dickey-Fuller . They offer practical advice for testing in the case where you wish to allow under the null. See also Kim and Perron (2009) for more recent work that directly tackles this issue.where are innovations, and is a lag polynomial representing the dynamics of the stationary and invertible ARMA error process, and is a drift parameter.
Note that the full impact of the break variables occurs immediately.In the second-step, let be the residuals obtained from the detrending equation. The resulting Dickey-Fuller unit root test equation is given by,where we use the for comparing to 1, , to evaluate the null hypothesis. These are standard augmented Dickey-Fuller equations with the addition of break dummy variables in Equation (37.44) to eliminate the asymptotic dependence of the test statistic on the correlation structure of the errors and to ensure that the asymptotic distribution is identical to that of the corresponding IO specification. See Perron and Vogelsang (1992b) for discussion.For a given test equation described above, you must choose a number of lags to include in the test equation, and you must specify the candidate date at which to evaluate the break. EViews offers a number of tools for you to use when making these choices.The theoretical properties of the test statistics requires that we choose the number of lag terms in the Dickey-Fuller equations to be large enough to eliminate the effect of the correlation structure of the errors on the asymptotic distribution of the statisticAll of the remaining methods are data dependent, and require specification of a maximum lag length .
A different optimal lag length is obtained for each candidate break date. Following Perron (1989), Perron and Vogelsang (1992a, 1992b), and Vogelsang and Perron (1998), is chosen so that the coefficient on the last included dependent variable lag difference is significant at a specified probability value, while the coefficients on the last included lag difference in higher-order autoregressions up to are all insignificant at the same level. The probability values for the s are computed using the .Based on an approach of Said and Dickey (1984) (see also Perron and Vogelsang, 1992a, 1992b), the approach uses an of the joint significance of the lag coefficients for a given against all higher lags up to . If any of the tests against higher-order lags are significant at a specified probability level, we set . If none of the test statistics is significant, we lower by 1 and continue. We begin the procedure with and continue until we achieve a rejection with , or until the lower bound is evaluated without rejection and we set .

Following the approach of Hall (1994) and Ng and Perron (1995), is chosen to minimize the specified information criterion amongst models with 0 to lags. You may choose between the Akaike, Schwarz, Hannan-Quinn, Modified Akaike, Modified Schwarz, Modified Hannan-Quinn. Note that the sample used for model selection excludes data using full set of lag differences up to .Minimize the Dickey-Fuller .Minimize or maximize () Maximize (), Minimize or Maximize (), Maximize (), Maximize F-statistic ().For the automatic break selection methods, the following procedure is carried out. For each possible break date, the optimal number of lags is chosen using the specified method, and the test statistic of interest is computed. The procedure is repeated for each possible break date, and the optimal break date is chosen from the candidate dates.When the method is minimize , all possible break dates are considered. For the methods involving or , trimming is performed to remove some endpoint values from consideration as the break date.
section describes the method for selecting lags for each of the augmented Dickey-Fuller test specifications (“Lag Selection”). You may choose between (AIC), (BIC), (HQC), , , , , , and lag specifications. For all but the lag method, you must provide a to test; by default, EViews will suggest a maximum lag based on the number of observations in the series. For the test methods (, ), you must specify a for the tests; for the lag method, you must specify the actual number of use using the edit field. section allows you to choose between the default and the specifications (“The Model”). section specifies the method for determining the identity of the breakpoint (“Break Date Selection”). for in the ADF test (), minimizing the for the intercept break coefficient (), maximizing the for the break coefficient (), maximizing the absolute value of the for the intercept break coefficient (), or providing a specific date (). , the output consists of a single column containing the statistics.